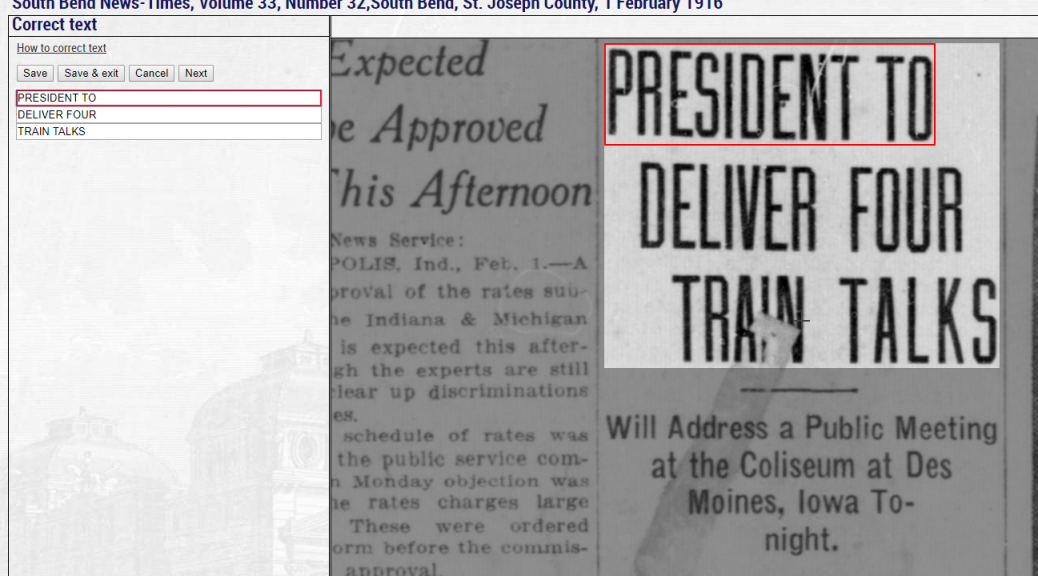
One of the most important features of Hoosier State Chronicles is the use of Optimal Character Recognition, or OCR. It is created by automated computer software that “finds” characters (letters, numbers, etc.) in digitized images and then transcribes them into searchable text. OCR allows users to search within the text of digitized newspapers for names, dates, or any other term that is relevant to their research. While OCR adds tremendous value to digitized materials, it doesn’t always correctly transcribe words or characters. You will frequently come across OCR that looks like the image below. (Click on images to enlarge them in separate tab.)
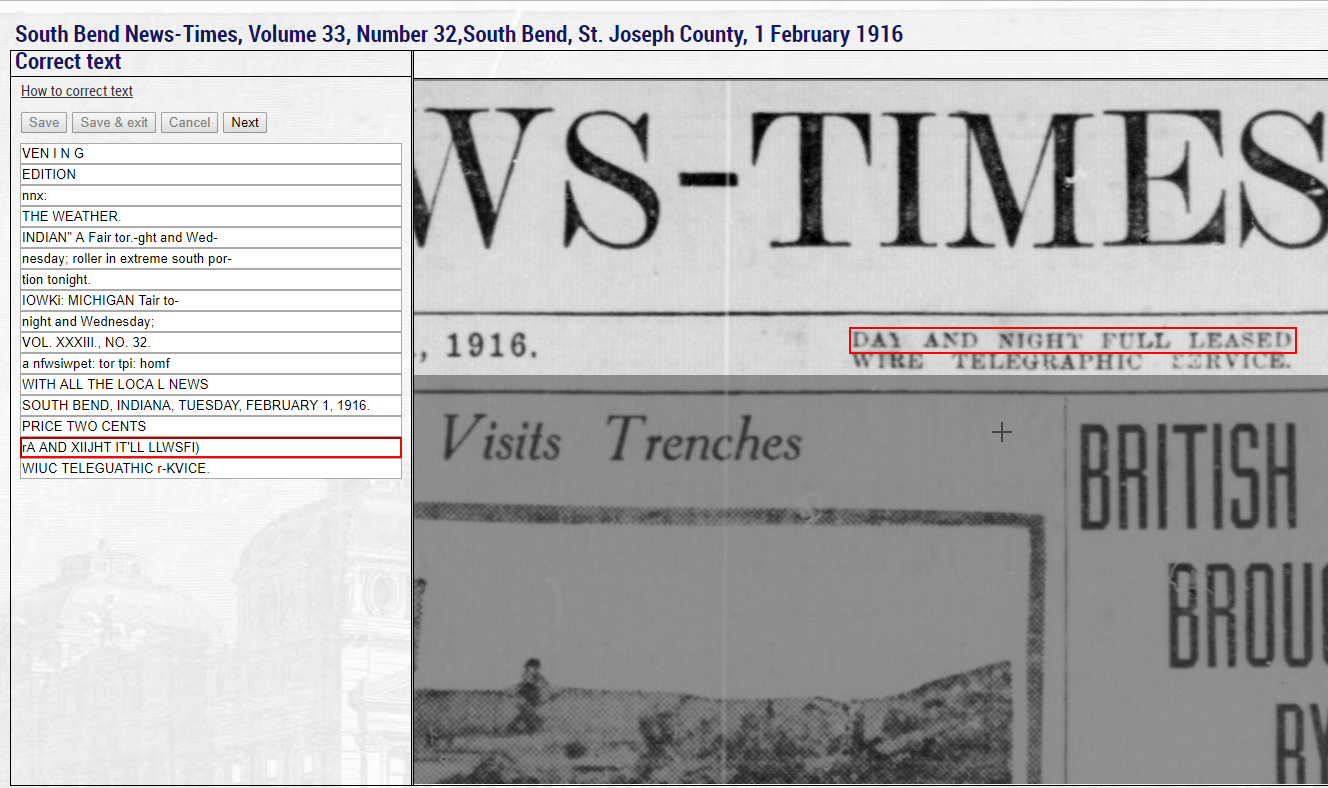
This is where our users come in. When you create a free account on Hoosier State Chronicles, you can actually edit the OCR text of a given page, which improves the functionality of our digitized newspapers. To date, our users have corrected over 315,000 lines of text; one user alone has corrected over 40,000 lines of text—more than anyone else! This blog post will show you how to create an account on Hoosier State Chronicles and how to correct OCR text in our digitized newspapers. With the tools provided here, we hope you will correct as many lines as possible. Who knows, you may even top the current record holder. Regardless of how many lines you correct, each one will make Hoosier State Chronicles a better platform for researchers delving into Indiana’s past through newspapers.
Creating a Free Account on Hoosier State Chronicles
Before you can edit OCR-generated text in Hoosier State Chronicles, you need to create a free account. To do this, click the “Register” link in the upper right-hand corner of the Hoosier State Chronicles homepage.
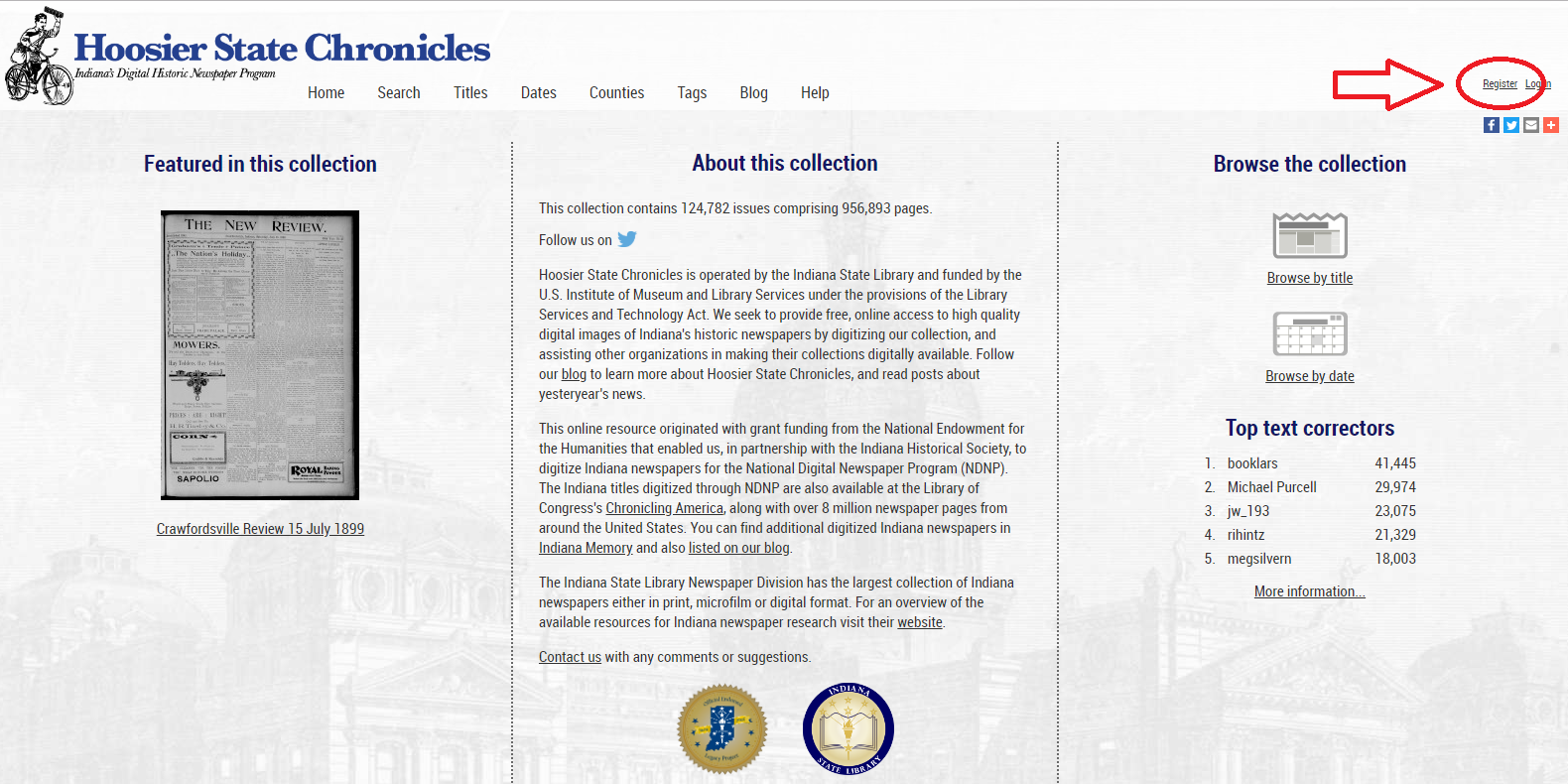
Fill in the required fields (email, display name, password) and click “go.” You’ll then receive an email to confirm your new account. Click the link in the email to confirm your account. You can now login via the account confirmation page and you’re ready to go!
OCR Text Correction
To correct OCR text, you can choose any issue or page you’d like. In this blog, we’ll work on the issue shown earlier, the February 1, 1916 edition of the South Bend News-Times. Choose a page of the issue either by clicking on the image itself or the page link on the left hand side. Once you’ve done that, you’ll see a “Correct this text” link; the text correction feature is accessed by clicking that link when viewing section text. This feature is split into two parts: the right side shows the page images that make up the document, and the left side is used for editing the lines of text.
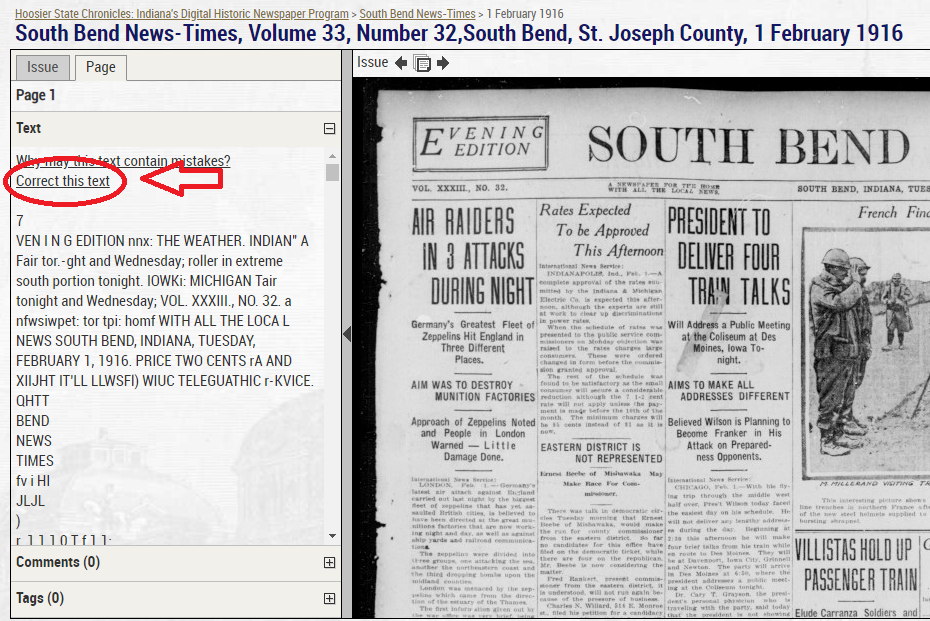
When you move over the page images on the right, sections of the page will be highlighted. You can change this view by dragging with the mouse, or zoom in/out using the buttons above the images on the right-hand side. Clicking a highlighted section will select it and generate a form for editing that specific section on the left-hand side of the page.

You can now correct the text line by line. A red box is displayed on the right-hand side to help you determine what text should be included in the line on the left-hand side. Once you have finished correcting the text, click “Save.” The changes you make will take effect immediately. Alternatively, clicking the “Cancel” button will discard any unsaved changes you have made.
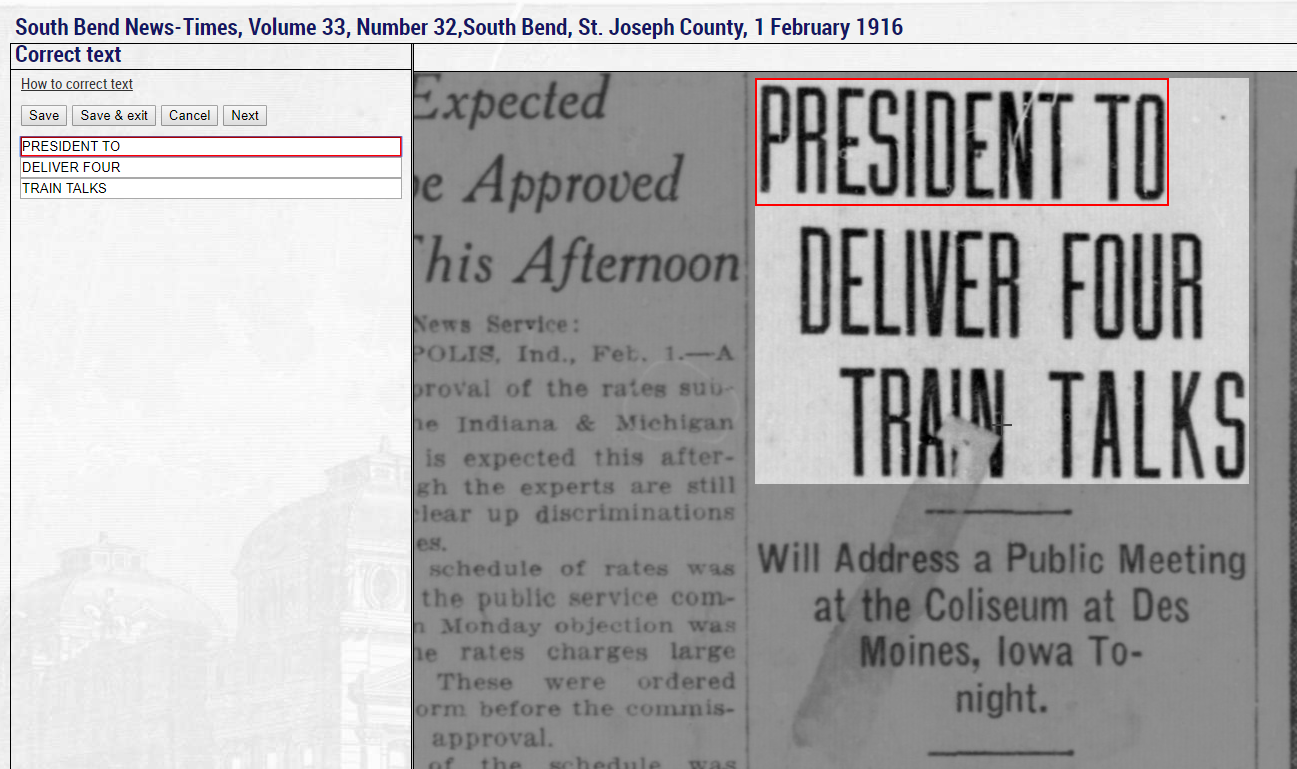
You can then make further corrections to the same block, move onto the next block by clicking the “Next” button, select another block in the right-hand side, or exit the text correction view by clicking the “Return to viewing mode” link. Clicking “Save & exit” instead of “Save” will save the changes and automatically return you to the normal viewing mode.
While our text correction feature is pretty robust, it has one limitation that we hope to change in the future. Currently, you can only edit existing fields generated by OCR; it doesn’t allow for the creation of new text fields. Even though this is a limitation, the OCR fields on our newspapers are fairly exhaustive and still give us substantial editing abilities.
Here’s another useful tip: many web browsers include spell-checking functionality and this can assist with your text correction by identifying misspelled words. If your web browser does not have this functionality, it’s likely there is a spell-checking add-on available (see your web browser’s help for information on how to install add-ons).

Now armed with the knowledge of text editing on Hoosier State Chronicles, you can improve the quality of our digital newspaper collection. Happy editing! If you have any other follow-up questions or concerns, please contact Justin Clark, Indiana State Library’s Digital Initiatives Director, via email at jusclark@library.in.gov.
Thanks to ISL’s Brittany Kropf for the blog’s title.
Like this:
Like Loading...





 Greetings Chroniclers!
Greetings Chroniclers!