We have several new titles from Greencastle, Milford, and Syracuse available for you through Hoosier State Chronicles, totaling 8,795 issues and 108,389 pages. This brings our total page count in Hoosier State Chronicles to 1,398,302!
We are proud to announce that the Nappanee Advance-News is now available on Hoosier State Chronicles! The collection, spanning 1879-2018, comprises 7,155 issues and over 84,000 pages. You can check it out here.
We are proud to announce that the Indianapolis Times is now available on Hoosier State Chronicles! The collection, spanning 1920-1952, comprises 10,283 issues and over 234,000 pages. The iconic daily newspaper, which ran for over fifty years, became known for its “crusading” journalism, exposing the collusion and corruption between the Indiana state government, governor Ed Jackson, and the Ku Klux Klan. The Timesearned the Pulitzer Prize in 1928 for “exposing political corruption in Indiana, prosecuting the guilty and bringing about a more wholesome state of affairs in civil government.” You can check it out here.
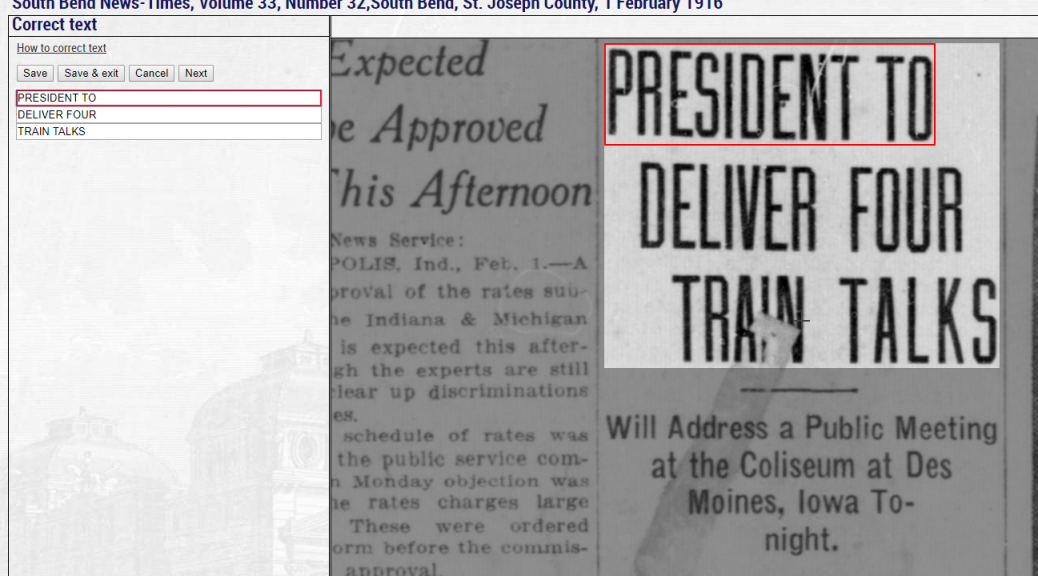
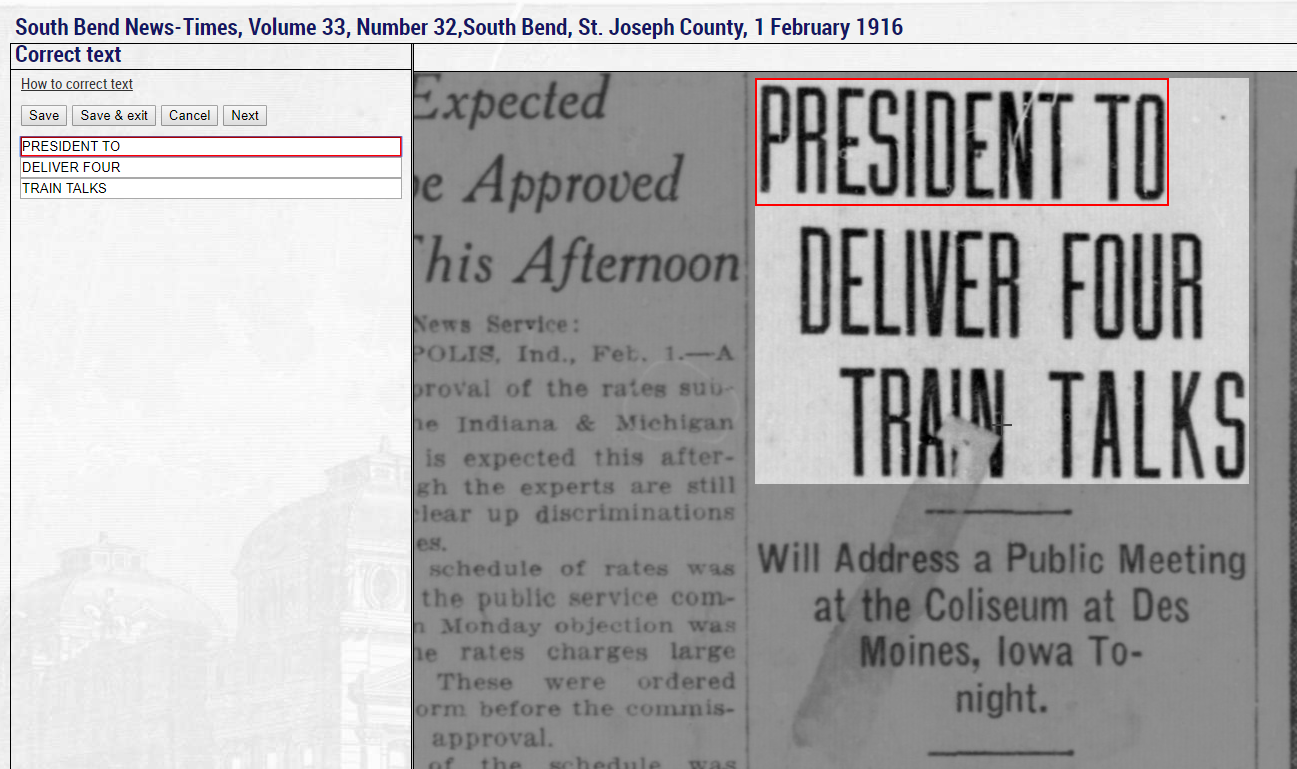
One of the most important features of Hoosier State Chronicles is the use of Optimal Character Recognition, or OCR. It is created by automated computer software that “finds” characters (letters, numbers, etc.) in digitized images and then transcribes them into searchable text. OCR allows users to search within the text of digitized newspapers for names, dates, or any other term that is relevant to their research. While OCR adds tremendous value to digitized materials, it doesn’t always correctly transcribe words or characters. You will frequently come across OCR that looks like the image below. (Click on images to enlarge them in separate tab.)
This is where our users come in. When you create a free account on Hoosier State Chronicles, you can actually edit the OCR text of a given page, which improves the functionality of our digitized newspapers. To date, our users have corrected over 315,000 lines of text; one user alone has corrected over 40,000 lines of text—more than anyone else! This blog post will show you how to create an account on Hoosier State Chronicles and how to correct OCR text in our digitized newspapers. With the tools provided here, we hope you will correct as many lines as possible. Who knows, you may even top the current record holder. Regardless of how many lines you correct, each one will make Hoosier State Chronicles a better platform for researchers delving into Indiana’s past through newspapers.
Creating a Free Account on Hoosier State Chronicles
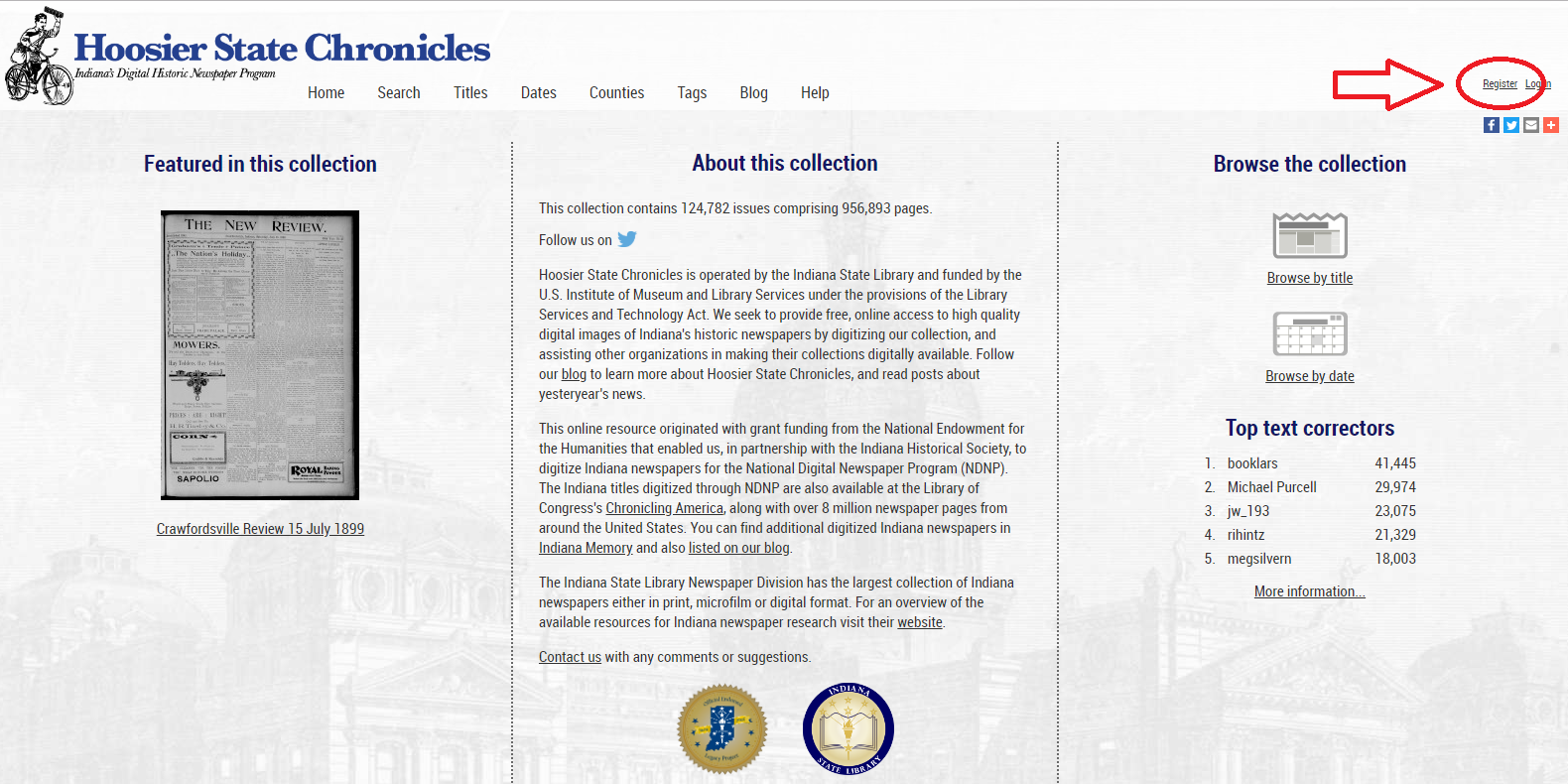
Before you can edit OCR-generated text in Hoosier State Chronicles, you need to create a free account. To do this, click the “Register” link in the upper right-hand corner of the Hoosier State Chronicles homepage.
Fill in the required fields (email, display name, password) and click “go.” You’ll then receive an email to confirm your new account. Click the link in the email to confirm your account. You can now login via the account confirmation page and you’re ready to go!
OCR Text Correction
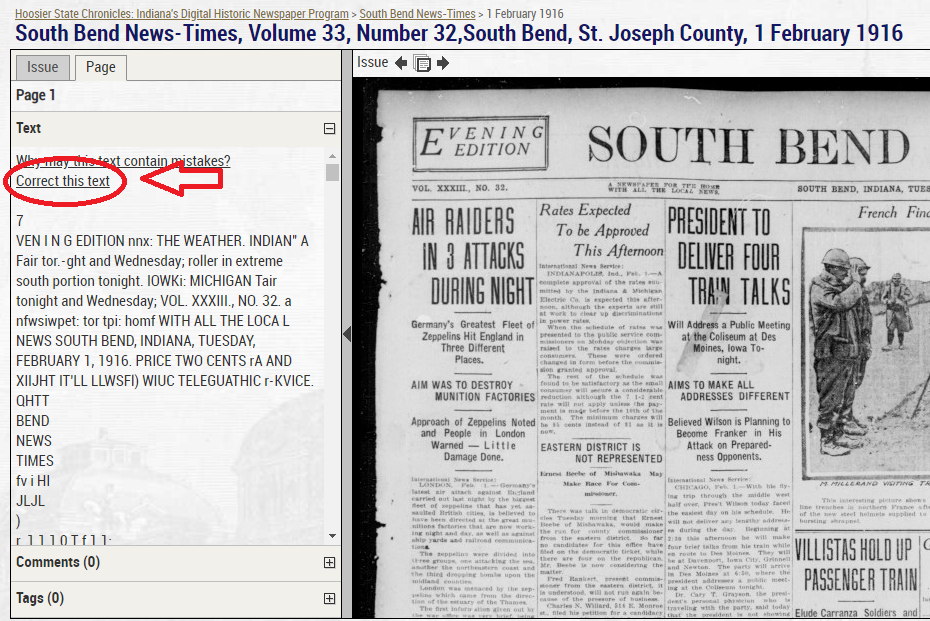
To correct OCR text, you can choose any issue or page you’d like. In this blog, we’ll work on the issue shown earlier, the February 1, 1916 edition of the South Bend News-Times. Choose a page of the issue either by clicking on the image itself or the page link on the left hand side. Once you’ve done that, you’ll see a “Correct this text” link; the text correction feature is accessed by clicking that link when viewing section text. This feature is split into two parts: the right side shows the page images that make up the document, and the left side is used for editing the lines of text.
When you move over the page images on the right, sections of the page will be highlighted. You can change this view by dragging with the mouse, or zoom in/out using the buttons above the images on the right-hand side. Clicking a highlighted section will select it and generate a form for editing that specific section on the left-hand side of the page.
You can now correct the text line by line. A red box is displayed on the right-hand side to help you determine what text should be included in the line on the left-hand side. Once you have finished correcting the text, click “Save.” The changes you make will take effect immediately. Alternatively, clicking the “Cancel” button will discard any unsaved changes you have made.
You can then make further corrections to the same block, move onto the next block by clicking the “Next” button, select another block in the right-hand side, or exit the text correction view by clicking the “Return to viewing mode” link. Clicking “Save & exit” instead of “Save” will save the changes and automatically return you to the normal viewing mode.
While our text correction feature is pretty robust, it has one limitation that we hope to change in the future. Currently, you can only edit existing fields generated by OCR; it doesn’t allow for the creation of new text fields. Even though this is a limitation, the OCR fields on our newspapers are fairly exhaustive and still give us substantial editing abilities.
Here’s another useful tip: many web browsers include spell-checking functionality and this can assist with your text correction by identifying misspelled words. If your web browser does not have this functionality, it’s likely there is a spell-checking add-on available (see your web browser’s help for information on how to install add-ons).
Now armed with the knowledge of text editing on Hoosier State Chronicles, you can improve the quality of our digital newspaper collection. Happy editing! If you have any other follow-up questions or concerns, please contact Justin Clark, Indiana State Library’s Digital Initiatives Director, via email at jusclark@library.in.gov.
Thanks to ISL’s Brittany Kropf for the blog’s title.
This article is based on a talk I gave at the Digital Public Library of America’s DPLA Fest conference on September 21, 2018.
Disclaimer: I am not a lawyer and this is not professional legal advice. This article is for educational purposes only. Please consult counsel concerning any potential digitization projects your institution is interested in pursuing.
Introduction
Good afternoon. Thank you very much for attending this session. I’m Justin Clark, Project Manager of Hoosier State Chronicles, our state-wide historic digital newspaper program at the Indiana State Library. We are a part of the National Digital Newspaper Program (NDNP), a joint venture between the Library of Congress and the National Endowment for the Humanities. To date, we’ve digitized nearly a million pages of historic Indiana newspapers, of which over 300,000 have gone into NDNP’s Chronicling America database of nearly 14 million digitized newspaper pages from across the county.
When digitizing historic newspapers for NDNP, one of the most important things to consider is whether the paper is under copyright. You could have picked the perfect title, had it approved by your institution, and completed all of the arduous work of collation, but if you don’t check its copyright status, your work could all be for naught. This is why a basic understanding of fair use, the public domain, copyright, and conducting copyright research is essential to any newspaper digitization project. This talk will provide a general overview of what fair use is, how it relates to newspaper titles, and how you can complete the necessary research to ensure your desired title for digitization is acceptable. Doing this work gives you not only an expanded scope of potential titles for digitization, but it also provides peace of mind that you won’t hear from any lawyers in the future, besides your institution’s counsel, of course.
Now, before we begin our stroll through copyright, I must say this. I AM NOT A LAWYER . . . nor have I played one on TV. This talk is only an educational overview of what I’ve learned about copyright research for digitizing newspapers. Other materials such as photographs, 3D objects, and written documents may not follow the same procedures or guidelines. It is imperative that you consult your institution’s legal counsel before making any concrete decisions to digitize anything. This saves you a visit from an irate lawyer who is upset that you’ve digitized materials that are still in copyright. And this little disclaimer saves ME a visit from an irate lawyer who got the call from the other one about copyrighted materials. In short, the only lawyer you want visiting your office should come from your institution. Now, with that out of the way, let’s start with fair use.
What Is Fair Use?
The Fair Use Logo, Wikipedia.
In the United States, copyright holders possess considerable legal rights for the protection of their intellectual property. This is a great thing – copyright holders can use their hard work to ensure an income and that scammers will keep their greedy hands off of work that doesn’t belong to them. But there are exceptions. One such exception to US copyright law plays a vital role in our emerging digital landscape: fair use. Fair use, according to the U.S. Copyright Office, “is a legal doctrine that promotes freedom of expression by permitting the unlicensed use of copyright-protected works in certain circumstances.” Essentially, fair use allows someone to use a copyrighted work for a completely different purpose than the copyright holder originally intended, which usually falls in the categories of “criticism, comment, news reporting, teaching, scholarship, and research.” These protections fall under Section 107 of the Copyright Act.
To determine whether or not a use of a copyrighted work is fair use, four general guidelines are followed. The first is the “purpose and character of the use.” Most of the time, if a person is using a copyrighted work for non-profit and/or educational purposes, it generally falls under fair use. This is especially the case if the use is “transformative” meaning that it “add[s] something new, with a further purpose or different character, and do[es] not substitute for the original use of the work.” In NDNP’s case, taking a newspaper which was originally created for immediate public consumption at a profit and transforming it into a digital historical artifact at no cost to the researcher usually falls under fair use. This guideline is not ironclad; sometimes, a copyright holder will object to their work being used in this way. Nevertheless, this guideline is generally applicable to NDNP and newspaper digitization as a whole.
Third, the “amount and substantiality of the portion used in relation to the copyrighted work as a whole” plays a role in deciding fair use. In other words, if a person just blatantly copied the entirety of a copyrighted work and then sold it for their own benefit, it would not be fair use. However, for material that falls under the public domain (more on that below), recreating the entirety of the work is more than fine and falls under fair use. NDNP projects often have syndicated columns and cartoons that are copyrighted but the newspaper as a whole is not copyrighted. In those instances, the amount of non-copyrighted work outweighs the copyrighted work and the digitization of a newspaper is then considered fair use. We will unpack this more in the copyright research section.
Finally, fair use is determined by the “effect of the use upon the potential market for or value of the copyrighted work.” Put simply, does the use of a copyrighted work ruin its value in the marketplace? In the case of digitizing newspapers, a newspaper’s value stemmed from its original sale date, which was years or decades before. If a newspaper title is already in the public domain, its original market value is already gone and can be used by others in a myriad of ways. For NDNP projects, turning a newspaper into a primary source historical document does not destroy the market value of the original paper nor does it harm copyrighted works therein (syndicated columns and cartoons). Potential researchers are using the digitized newspapers for scholarly purposes, not for the resale of copyrighted material. As with the other three guidelines, the “market value” guideline is generally met.
This overview of fair use is not exhaustive. Definitely review material on fair use from the U.S. Copyright Office and the Copyright Alliance for more information.
What is “Public Domain”?
Public Domain Logo
Alongside fair use, a clear conception of public domain is essential for working on NDNP-related projects. Works in the public domain, according to the Stanford University Library, are:
. . . creative materials that are not protected by intellectual property laws such as copyright, trademark, or patent laws. The public owns these works, not an individual author or artist. Anyone can use a public domain work without obtaining permission, but no one can ever own it.
A work enters into the public domain via three avenues: it can’t be copyrighted (i.e., titles, names, facts, ideas, government works), the creator of the work places it in the public domain, or its copyright term has expired. With NDNP, the last of these three is the most important.
Have you ever wondered why the vast majority of NDNP’s content, and most digitized newspaper content, ends around 1923? It’s for a very simple reason: all works published in the United States before 1923 are in the public domain. No copyright research is necessary for this material; it’s free and clear for you to use. However, NDNP announced in 2016 that it has expanded its date range for newspaper titles, from 1836-1922 to 1690-1963. Thus, post-1923 works are in the public domain if a copyright claim was never filed from 1923 through 1977 or if the copyright was never renewed from 1923 through 1963. All NDNP projects that follow these public domain guidelines will easily determine if their potential title is ready for digitization.
Now that you know how fair use and the public domain work, you can begin the necessary research to determine the copyright status of a newspaper title. Here in Indiana, we wanted to know the copyright status of one of Indianapolis’s premier papers of the 20th Century: the Indianapolis Times. The Times ran from 1888 (when it was titled the Sun) until 1965, a pretty impressive run for a daily metropolitan newspaper. From 1922 until its end, the Times was owned and operated by Scripps-Howard, a major publishing corporation based out of Cincinnati, Ohio. Knowing that such an influential publishing company owned the Times from 1922 until 1965 put an increased responsibility on us to make sure that the paper was either in the public domain and/or that its digitization would be considered fair use.
Indianapolis Times, October 11, 1965, Indiana State Library Newspaper Microfilm Collection.
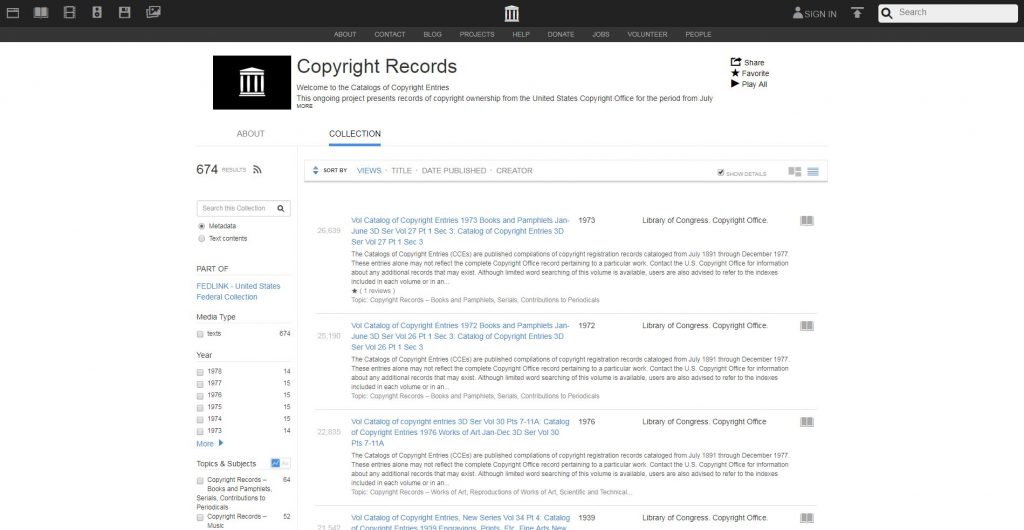
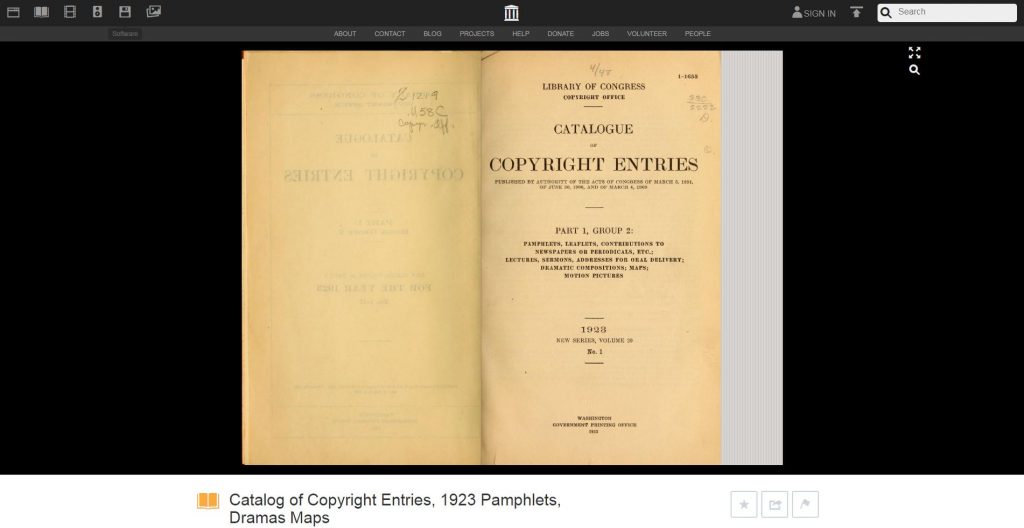
The Catalog of Copyright Entries (1906-1977) is available at Internet Archive (www.archive.org) in a readable, PDF format. It comes with Optimal Character Recognition (OCR), so it is text-and-word searchable. To begin, view the 1923 Catalog of Copyright Entries, Part 2, which provides the copyright and copyright renewal for all periodicals published in the United States that year. For all the following years, look for the volume devoted to periodicals. In the search field, type the name of your title. If nothing comes up, search the catalog’s index for the title. If nothing is there, check the title within the book in the new copyright section as well as the renewal section. If nothing comes up, your newspaper title filed neither a new copyright nor a copyright renewal and it is in the public domain. Consult all remaining years of the catalog (in the periodical section) for any new copyright notices or copyright renewals. If you do find that your title was published with a copyright notice and a renewal from 1923-1963, it is not in the public domain and will remain under copyright for 95 years after the publication date. However, if the title was published from 1923-1963 with an initial copyright notice but was not renewed during that time, it is in the public domain and you are free to digitize.
Catalog of Copyright Entries, Library of Congress/Internet Archive. This is an example of the periodicals section of the catalog.
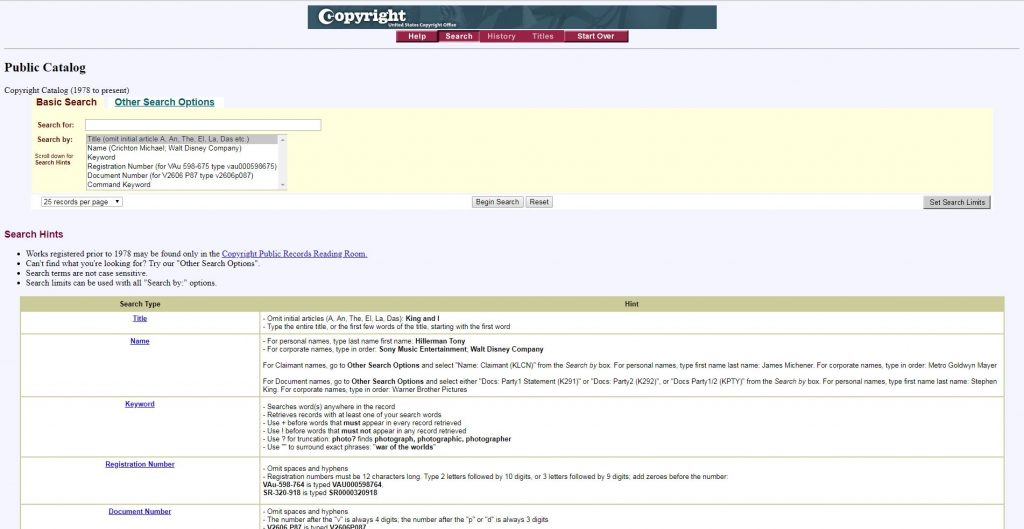
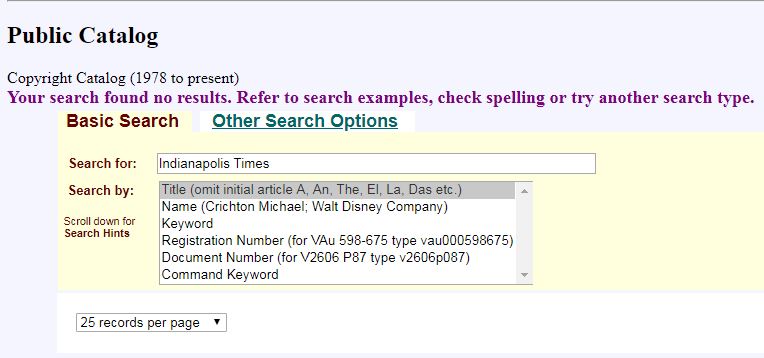
If you need to check anything after 1977, use the online Public Catalog of Copyright Entries, which covers 1978 to the present. This search is much easier than combing through the scanned versions at the Internet Archives. All you have to do is type in your title in the search bar; if you get no results, no copyright renewals were filed and you’re good to move forward. If there are copyright renewals, the title will remain under copyright for 95 years after its initial publication date.
Online Catalog of Copyright Entries, Library of Congress.
For our research, we started with 1922, the year that Scripps-Howard Newspapers purchased the Times and the final year it could have been in the public domain (this research was done in 2017, before the public domain covered 1923). According to listings in the Catalog of Copyright Entries and the Public Catalog of Copyright Entries, Scripps-Howard Newspapers never filed the Times for copyright between 1922-1965 or for subsequent renewals from 1965-present. Therefore, the Times as a complete newspaper is within the public domain and eligible for digitization.
Online Catalog of Copyright Entries, Library of Congress. A search for “Indianapolis Times” yields no results, which means that its copyright was never renewed after 1978.
But your search doesn’t end there! The copyright of individual articles and syndicated content also needs to be established. Library of Congress policy for NDNP has generally been that individually-copyrighted content within the “context” of an entire newspaper in the public domain is not a problem, so long as it doesn’t account for over 50% of the entire work. This rule is a recommendation and not an absolute policy. It is still up to you as an NDNP awardee, your institution, and your legal counsel to establish the proper procedures for such content.
Catalog of Copyright Entries, Library of Congress/Internet Archive. This is an example of the book and/or pamphlet section of the catalog, where copyright information on contributions to periodicals is located.
With our research of the Times, one type of syndicated content that showed up right away within copyright research was the Sunday supplemental, with PARADE magazine being an applicable example in the Times. From 1963-1965, PARADE was published with Sunday issues of the Times; it was copyrighted when it originally ran (and included in the Catalog of Copyright Entries) and was subsequently renewed (and included in the Public Catalog of Copyright Entries). As such, we decided not to include this supplemental in our NDNP deliverables. Regarding individual articles, we found 32 copyright listings in the Catalog of Copyright Entries from 1922-1965; only the initial copyright was listed and no renewals were found. These were then cross-referenced in the online Public Catalog of Copyright Entries to check for post-1978 renewals; none were found. These articles accounted for less than 10% of the entire field of research, way less than the more than 50% threshold for fair use. (So long as you consult your institution and its legal counsel.)
An example of PARADE magazine’s copyright notice from 1964. Supplementals like this are not in the public domain.
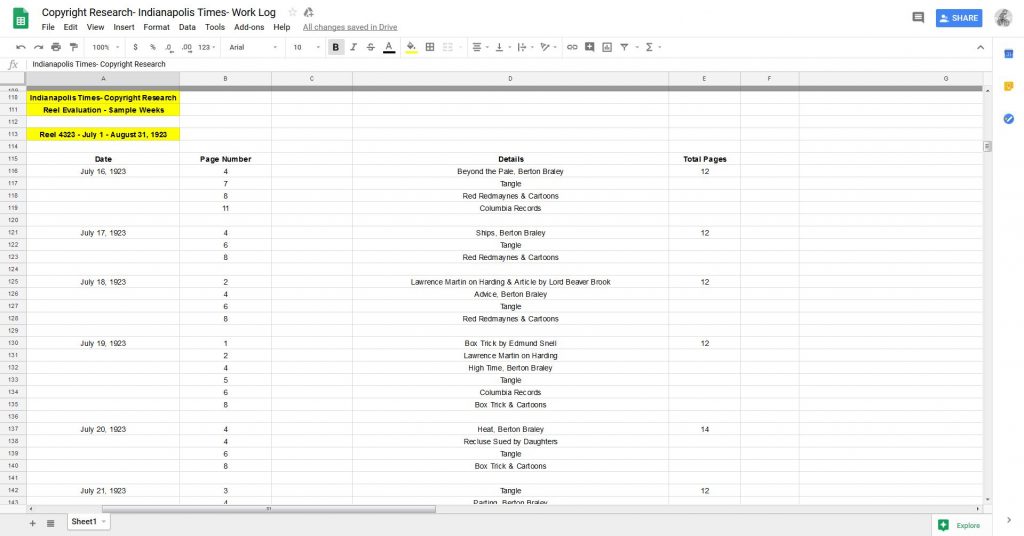
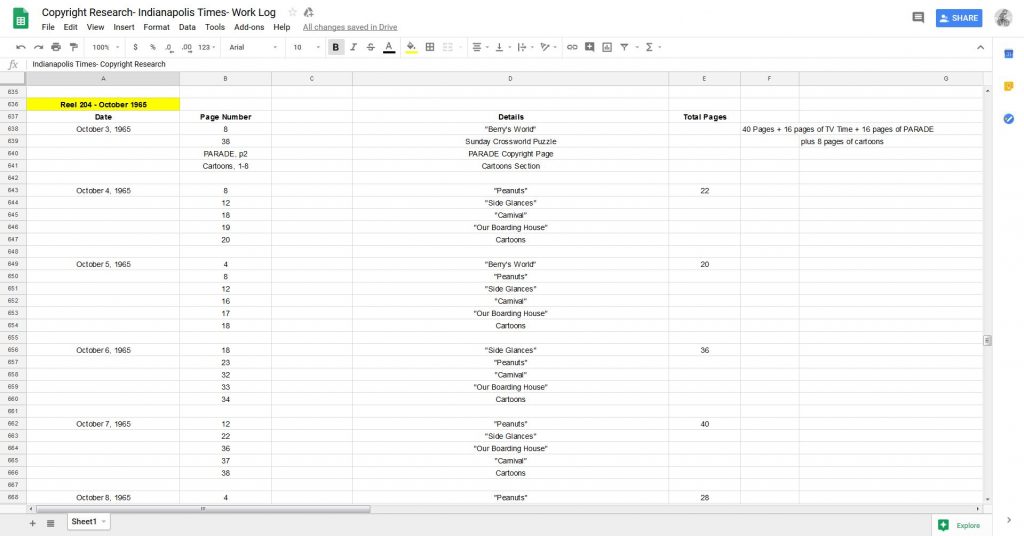
Now that you’ve thoroughly gone through the Catalogs, it’s also good policy to review the title’s microfilm. Here’s what we did. We chose three reels from each decade of the Times from 1923 to 1965 and scoured them for copyrighted content. We concluded that the vast majority of material on these reels fell within the public domain, in keeping the Times’s policy on copyright. As for what was copyrighted, it was mostly advertisements for still-existing products (Columbia Records, Bayer Aspirin), syndicated cartoons (individual cartoons scattered throughout the paper as well as one full page an issue), serialized fiction, and syndicated columns. These materials contained a copyright symbol and text, indicating its status. We concluded that these entries constituted a small minority of the newspaper content and largely will not affect the proprietary interests of the copyright holders (seeing as the content in question was digitized from second-generation microfilm, which itself come from first-generation preservation microfilm based photographed pages; the loss in resolution and quality should not urge copyright holders to pursue legal action). You can do more or less with your title’s microfilm than we have, but this should be enough to establish a broad consensus on your title’s copyright status.
A Bayer Aspirin ad from 1925. This was a copyrighted aspect of the Indianapolis Times that we reviewed when combing the microfilm collection.
Once you’ve done all of these procedures, it is best to draft a full report of your research and findings to your NDNP advisory board, as well as your institution’s legal counsel. Make sure to be as detailed as possible – this ensures they fully understand what you’ve done and saves you the trouble of having to answer a bunch of follow-up questions. For our research on the Times, I and my project director drafted our report and then sent it to the aforementioned parties. From there, we received approval to digitize the Times.
An example of syndicated and copyright cartoons from the Indianapolis Times.An example of copyrighted serialized fiction in the Indianapolis Times.
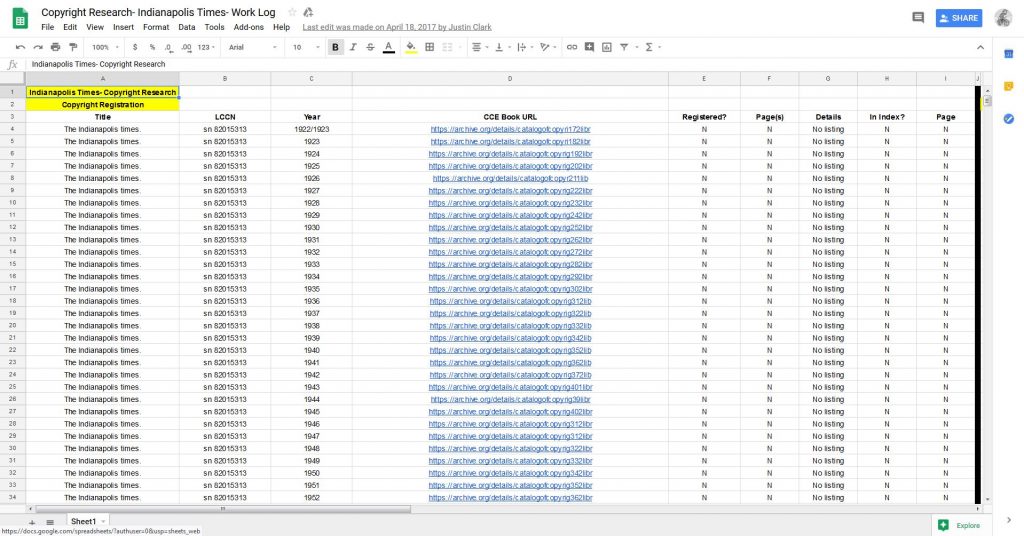
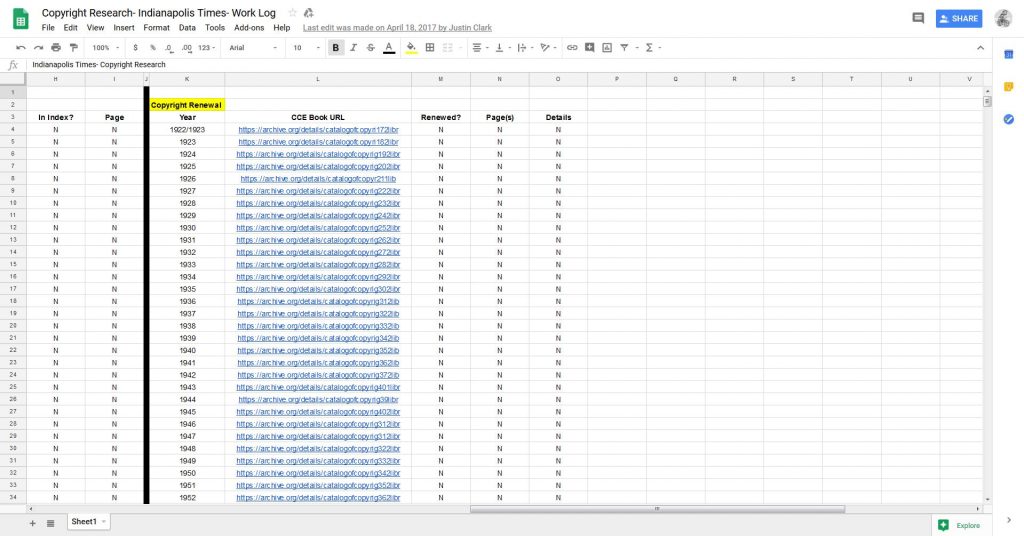
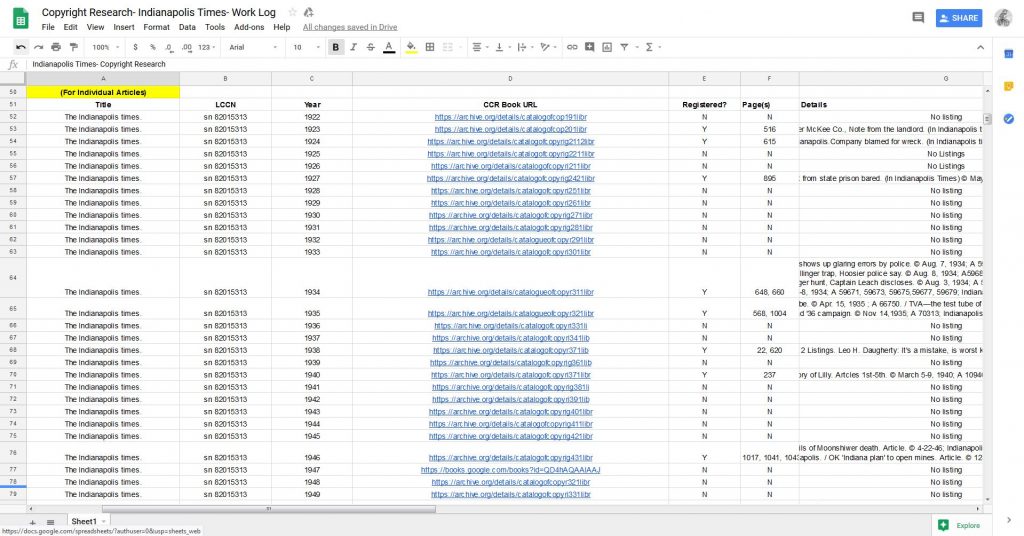
One more tip for your research: make sure to keep detailed notes of everything you do. You will be going through a lot of newspapers, so it will help you keep things straight. It also provides a paper trail that your institution’s leadership and legal counsel can consult if necessary. I suggest using Google Sheets and Docs to complete this research. It will be in the Cloud and can be easily shared with anyone who would like to see it. If Google is not your fancy, use Microsoft Office and back up your work to the Cloud or another hard drive. You don’t want to work diligently for months to have all of it lost because of computer issues.
Examples of how I documented all my work. You will be going through a lot of newspapers, so it will help you keep things straight. It also provides a paper trail that your institution’s leadership and legal counsel can consult if necessary.
Conclusion
Digitizing newspapers has been one the most rewarding things I’ve worked on in the public history and cultural heritage space. Seeing a title like the Indianapolis Times digitized and made available for researchers to use, for free, has been a real privilege. But all of this could not have happened without doing the long and often-tedious work of copyright research. Researching a title’s copyright ensures that it is free and clear for you to digitize—and a lawyer from King Features or PARADE magazine won’t come knocking on your door. Yet, copyright research can also be very rewarding. It gives you a big-picture view of the title you’re considering for digitization. You’ll see who its original audience may have been, the kinds of stories they covered, and how it fits in the context of your state’s, and the country’s, history. This, among many other things, makes copyright research worth it. Thank you.
There’s one tradition that often gets misunderstood during this time of year, especially among us Americans: it’s using the phrase, “Happy Holidays.” Some folks think that using this term, instead of saying “Merry Christmas,” “Happy Hanukkah,” or any other specific holiday, diminishes the importance of this time of year. They think the term is too recent, modern, and without a tradition of its own. However, when one does a little digging, you’ll soon find out that the phrase has a long and treasured history here in the United States and even in the Hoosier State.
Richmond Palladium and Sun-Telegram (Daily): January 1, 1912 – Mar 30, 1912, July 1, 1912 – September 30, 1912, October 1, 1913 – December 31, 1913, May 8, 1916, April 21, 1922-December 30, 1922


 Greetings Chroniclers!
Greetings Chroniclers!